极速部署!GpuGeek提供AI开发者的云端GPU最优解
2025-03-18 09:53:36来源:今日热点网
在AI开发领域,算力部署的效率和资源调度的灵活性直接影响研发进程与创新速度。随着模型复杂度的提升和全球化协作需求的增长,开发者对GPU云服务的核心诉求已从单纯追求硬件性能,转向对部署效率、跨区域协作支持及全流程开发体验的综合考量。GpuGeek作为专注于AI基础设施的平台,凭借其“极速部署”能力与深度优化的服务体系,正成为开发者的云端首选。

一、秒级启动:从注册到运行,30秒开启使用
传统GPU云服务常因繁琐的环境配置、复杂的计费模式拖慢开发节奏,而GpuGeek通过多项创新技术实现“零等待”体验,让用户跳过环境部署“深水区”,直击核心开发任务,实现效率提升。
极简流程:注册账号、选择预置镜像(支持TensorFlow/PyTorch等主流框架)、创建GPU实例三步操作,最快30秒即可进入使用界面。
动态算力伸缩:GpuGeek支持8卡并行计算(平台从消费级的RTX 4090到专业级的A5000/A800,再到最新的H100集群,全系列GPU资源应有尽有),用户可根据任务需求一键调整算力规模,无需重复配置环境。
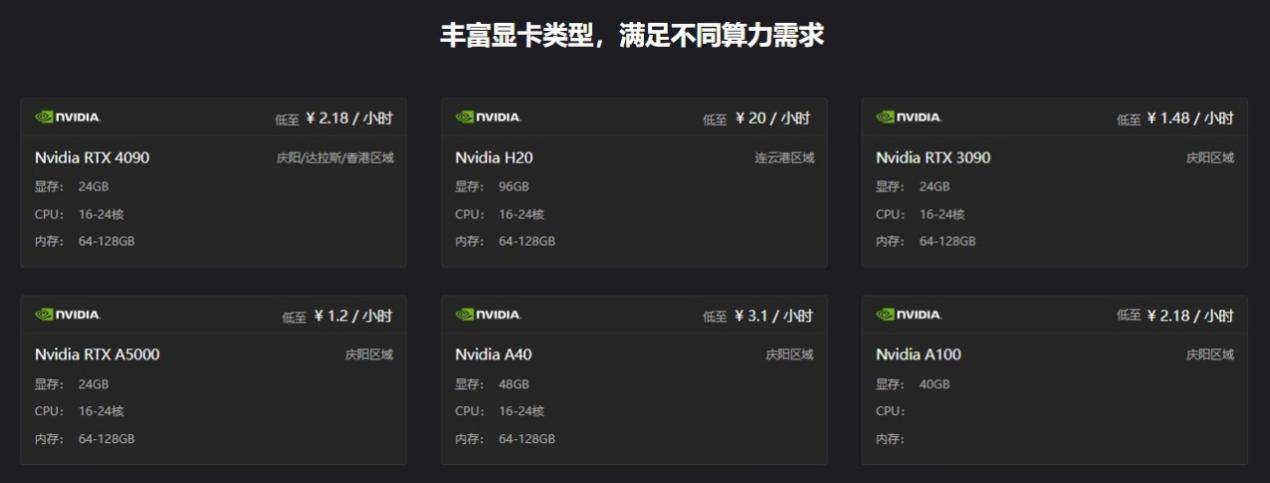
按需计费:GpuGeek秒级计费模式精准匹配开发周期,避免资源闲置浪费,尤其适合间歇性训练或临时性算力需求场景。
二、全球节点覆盖:破解跨国部署三大痛点
全球化AI协作面临镜像加载慢、推理延迟高、数据合规难等挑战。GpuGeek通过“全球镜像库+智能节点调度”提供一站式解决方案,无论是欧洲团队训练模型,还是亚太团队通过本地节点实时调用API,其数据同步延迟都能压缩至毫秒级。
跨国加速:GpuGeek在香港、达拉斯等海外节点实现模型镜像秒级下载,推理延迟低至0.5秒,满足欧洲、亚太等地区的实时响应需求。
数据合规保障:一键完成数据存储与传输的本地化合规操作,规避跨境法律风险。
三、镜像生态与存储优化:加速模型全生命周期
从模型微调到大规模训练,GpuGeek通过软硬协同设计缩短数据读写与部署周期,引入kata虚拟化技术强化容器隔离性,兼顾安全与性能,保障多租户场景稳定性。
预置镜像池:GpuGeek提供100+预加载模型镜像(如OpenManus、阿里千问QwQ-32B等),覆盖CV、NLP、多模态领域,支持一键调用。
NVMe本地缓存:模型文件直接预载至本地硬盘,读取速度较传统云盘提升3-5倍,大幅减少等待时间。
开放生态共建:开发者可发布自定义镜像赚取积分,或通过GpuGeek社区互助快速获取稀缺框架配置,形成“开发-共享-复用”的正向循环。
四、开发者友好:从资源到社区的全链路激励
GpuGeek主张让开发者专注创新,通过活动与社区构建降低使用门槛:
成本优化:GpuGeek3月限时活动中,A5000 24G GPU低至0.98元/时,中小团队亦可负担专业级算力。
激励体系:用户参与“云大使”推广、镜像创作、技术内容征集等活动,可兑换现金、代金券或免费算力,实现“以技养研”。
开放社区:开发者可交流调优技巧、共享数据集,GpuGeek鼓励用户在社区中积极交流创作灵感、分享实践经验,共同推动技术生态的繁荣发展。
快,是AI时代的核心竞争力。在AI技术迭代速率以月为单位的今天,GpuGeek通过极速部署能力、全球化资源布局、开放镜像生态及开发者优先理念,重新定义了GPU云服务的效率标准。无论是个人开发者的快速实验,还是企业级模型的跨国协同,其“30秒启动、全球无感切换、数据-训练-部署全链路加速”的特性,均能为用户赢得宝贵的创新时间窗口。选择GpuGeek,本质是选择一种更敏捷、更自由的AI开发方式——在这里,算力不再是瓶颈,创造力才是唯一边界。返回搜狐,查看更多
关键词:
责任编辑:hnmd004
- 极速部署!GpuGeek提供AI开发者的云端GPU最优解2025-03-18
- 四川尊杰新材料有限公司:全方位服务引领全2025-03-17
- 新讯×鸿蒙 | HDD·春日鸿蒙生态伙伴论坛2025-03-17
- 万元奶粉免费送,金领冠为三孩家庭加“育儿2025-03-17
- 四川尊杰新材料有限公司:全屋定制服务优势2025-03-17
- 四川尊杰新材料有限公司:演绎中式装修风格2025-03-17
- 德国朗乐福携新品引爆深圳国际家具展,盛启2025-03-17
- 政府、复星合力赋能,舍得酒业打造酒旅融合2025-03-17
- 携手守护儿童健康,上海六一儿童医院与会铁2025-03-17
- 朗诗德亮相2025阿姆斯特丹国际水处理展览会2025-03-17
- 振东五和养生酒:国家降尿酸专利引领健康饮2025-03-17
- 中能国新集团助力新建零碳产业园区:投归建2025-03-17
- 嘉兴袁梦装饰材料有限公司:家装整装,质量2025-03-17
- 嘉兴袁梦装饰材料有限公司:全屋整装,演绎2025-03-17
- 嘉兴袁梦装饰材料有限公司:全屋定制,空间2025-03-17
- 声光电项目修护有救了!绽妍联合皮肤专家权2025-03-17
- Motiva魔滴(梦萦)亚太峰会 揭秘第六代假2025-03-17
- 上海鼎植口腔25年春季种牙节暨摄影大赛启动2025-03-17
- 楔形的基本要义是什么?旗形和楔形的区别是2025-03-17
- 股票退市后如何处理?退市后多久才能去三板2025-03-17
- 股票怎么变成st的呢?ST是年报后还是中报后2025-03-17
- 股票融资高说明什么?股票融资净偿还增加是2025-03-17
- 丰田汽车金融一键激活丰田全球畅销车型卡罗2025-03-17
- 股票净现比是什么意思?净现比一般多少正常2025-03-17
- 股票怎么看价格呢?股票价值三种计算公式是2025-03-17
- 股市里大额订单的卖出策略是什么?订单分解2025-03-17
- 股票交易执行的速度受哪些因素影响?股市中2025-03-17
- 天下泽雨霍山石斛:荣获3.15消费者满意品牌2025-03-17
- 股票卖出要多久?涨停后还能卖出吗?2025-03-17
- 2025医美头条 | 智美全国首发精英男系列2025-03-17




